MySQL初心者が勉強してみて学んだことのまとめ
最近バックエンドの勉強を始め、MySQLを触る機会があったが学習ゼロだったので
学んだことを記事にしていく。
これは自分の学習備録の記事です。
MySQLとは?
MySQLとは、世界で最も利用されているデータベース管理システムです。
大容量のデータに対しても高速で動作し、便利な機能がたくさんあるので、非常に実用性が高くなっています。
また、オープンソースなので非商用利用であれば無償で使用できるため、初心者でも導入しやすく扱いやすいため
非常に人気の高いデータベース管理システムです。
そもそもデータベースとは?
データベースとは、情報を体系的に収集、整理、保存し、効率的に管理・利用するためのシステムです。
データベースというワードを聞くとIT技術を持つエンジニアしか作れない・操作できないという印象を持つ人も多いと思います。ですが業務に関するデータを管理しているMicrosoft Excelなどの表計算ソフトや、カテゴリーごとに分類された文書や書類、取引先や顧客に関する住所録などは、データベースの要素を持っています。
例えば商品を管理するための商品マスタ(商品台帳)はデータベースのひとつです。
大規模なWebサイトやWebアプリケーションではさまざまなデータを管理する必要があり、信頼性の高いデータベースシステムの構築は必要不可欠となっています。
MySQLはその代表例のひとつであり、CMS(コンテンツ管理システム)の1つであるWordPressに組み込まれていることでも有名です。WordPressは企業サイトやブログの制作・運営に幅広く利用されており、そのバックエンドでMySQLがコンテンツのデータ管理を担っています。
SQLとMySQLの違い
「SQL」と「MySQL」は名前も似ているため混同されやすいですが、別のものです。
- SQL:データベースを操作するプログラミング言語
- MySQL:データベース管理システムの一つ
SQLはデータベースを操作するプログラミング言語で、MySQLはSQLを使って操作するデータベースシステムのことです。
つまり、MySQLに保管されているデータを、SQLを使ってWebアプリなどの情報を表示したり、格納などの処理を行うことができます。
MySQLの特徴やメリット
MySQLは多様なニーズに対応できるデータベースとして幅広い分野で採用されています。
MySQLを採用するメリットについて、データベースの構造上の特徴や独自の強みを観点に紹介します。
一貫性の高いデータ管理が可能
MySQLは、リレーショナルデータベース(RDBMS)という表形式のデータベース構造をしており、一貫性があり、信頼性の高いデータ処理が可能という特徴を持っています。
テーブルごとにデータ形式やルールを明確に定義しているため不適切なデータが混入しにくく、複数のテーブルの関連付けもできるため、データ間の関係も明確に表現することができます。
例えば顧客管理シルテムでは、顧客の基本情報(顧客ID、名前、年齢など)をひとつのテーブルに、購買履歴(顧客ID、商品、日時など)を別のテーブルに保存できます。顧客IDという共通の情報を通じて、テーブル同士の情報を関連づけることで、さまざまな角度での情報分析が可能になります。
一方で、事前にデータ構造を厳密に定義するがゆえに、後からの変更が難しいという欠点もあります。
オープンソースでフリーで使える
データベース管理システムは高機能だと有料の場合が多いですが、MySQLはオープンソースなので無料で使えます。
学習目的での利用はもちろん、企業にとってもコスト削減の効果的な手段となります。大規模なベータベース管理が必要な場面でも、高額な投資を避けられるのは大きなメリットです。
資金が十分でないスタートアップ企業や個人でも簡単に利用することができます。
さまざまな言語に対応している
MySQLはPHP、C++、Ruby、Javaなどのさまざまな言語と連携することができます。
そのため、開発者はプロジェクトの要件や自分好みの言語を選択して、データベースの操作をすることができます。
高性能で処理が速い
リレーショナル型の中でも比較的少ないリソースで高速な処理が可能です。特に読み取り操作が多くあるシステムに適しており、大規模なWebアプリケーションでよく利用されます。
拡張性が高い
MySQLは複数のストレージエンジン(例: InnoDB、MyISAM)をサポートしており、用途に応じて適切なエンジンを選択することで性能と機能を最適化することができます。
また、大規模なテーブルを小さあな部分に分割して管理するパーティショニングや、複数のサーバーを追加して処理能力を分散させる水平スケーリングを活用することで、大規模データを効率的に管理し、高い拡張性を実現できます。
MySQLの環境構築
以下ではMsSQLのインストールからローカル環境に構築する方法をご紹介します。
今回はMac OSでの構築となります。
大まかな流れ
- Homebrewをインストール
- MySQLをインストール
- MySQLの起動
- DB作成
の流れで進めていきます。
1.Homebrewをインストール
Homebrewとは?
アップル(またはあなたのLinuxシステム)が提供していないあなたの必要なものをインストールできます。
Macのターミナルを使用しコマンドでさまざまなソフトをインストールしたりする際に必要なものです。
今回はそのHomebrewを使用して進めていきます。
Homebrewをインストール
公式サイトにあるように、下記のコマンドを使用してインストールします。
/bin/bash -c "$(curl -fsSL https://raw.githubusercontent.com/Homebrew/install/HEAD/install.sh)"下記のようにインストールが始まります。
その際にパスワードを入力する必要があるので入力してEnterを押すとインストールが始まります。
インストールが完了したら下記のコマンドでバージョンの確認ができます。
brew -v下記のようにバージョンが表示されていればインストールは完了です。
brew -v
Homebrew 4.3.242.MySQLをインストール
続いてMySQLをインストールします。
下記コマンドをターミナルで入力します。
brew install mysqlこちらもインストールが完了したら下記のコマンドでバージョンの確認ができます。
mysql --version問題なければ以下のように表示されます。
mysql Ver 9.4.0 for macos15.4 on arm64 (Homebrew)3.MySQLの起動
ここまではMySQLのダウンロードまで記述してきましたがここからは実際に起動し、テーブルの作成等も進めていきます。
MySQLはインストールしただけでは起動していません。
利用する場合は起動をしましょう。
MySQLの起動
MySQLを使用する際には下記コマンドで起動します。
mysql.server start起動すると下記のように「SUCCESS!」と表示されます。
mysql.server start
Starting MySQL
.. SUCCESS! MySQLの停止
起動したMySQLは使用しない場合は下記コマンドで都度停止しておきましょう。
mysql.server stop停止すると下記のように表示されます。
mysql.server stop
Shutting down MySQL
. SUCCESS! MySQLにログインする
下記コマンドでMySQLにログインしましょう。
mysql -urootMySQLのバージョン確認
下記コマンドでバージョンの確認が可能です。
mysql> show variables like 'version';
+---------------+-------+
| Variable_name | Value |
+---------------+-------+
| version | 9.4.0 |
+---------------+-------+
1 row in set (0.010 sec)
MySQLのユーザー確認
下記コマンドでユーザーの確認が可能です。
mysql> select user();
+----------------+
| user() |
+----------------+
| root@localhost |
+----------------+
1 row in set (0.001 sec)ユーザーの作成を行う
下記ユーザーを作成してみます。
ユーザー名:fuga
パスワード:hoge
mysql> create user 'fuga'@localhost identified by 'hoge';
Query OK, 0 rows affected (0.013 sec)ユーザーの再確認
fugaが作成されていることを確認。
mysql> select user, host from mysql.user;
+------------------+-----------+
| user | host |
+------------------+-----------+
| fuga | localhost |
| mysql.infoschema | localhost |
| mysql.session | localhost |
| mysql.sys | localhost |
| root | localhost |
+------------------+-----------+
5 rows in set (0.004 sec)※ユーザーの削除は下記コマンドで行う。
mysql> drop user 'fuga'@localhost;
Query OK, 0 rows affected (0.003 sec)4.DBの作成
下記コマンドで「mydb」というデータベースを作成していきます。
mysql> create database mydb;
Query OK, 1 row affected (0.011 sec)下記コマンドでmydbというデータベースが作成されたことを確認できます。
mysql> show databases;
+--------------------+
| Database |
+--------------------+
| information_schema |
| mydb |
| mysql |
| performance_schema |
| sys |
+--------------------+
5 rows in set (0.009 sec)作成したDBにチェックアウト
テーブル等を作成する前にどのDBを使用するか下記のように宣言する必要があります。
mysql> use mydb
Database changedテーブルの作成
今回は'users'というテーブルを作成します。
mysql> create table users(
id INT(10) NOT NULL,
name VARCHAR(30) NOT NULL,
PRIMARY KEY(id)
);
Query OK, 0 rows affected, 1 warning (0.012 sec)テーブルの作成に成功しました。
mysql> desc users;
+-------+-------------+------+-----+---------+-------+
| Field | Type | Null | Key | Default | Extra |
+-------+-------------+------+-----+---------+-------+
| id | int | NO | PRI | NULL | |
| name | varchar(30) | NO | | NULL | |
+-------+-------------+------+-----+---------+-------+
2 rows in set (0.005 sec)テーブルにデータを挿入
今回は"hoge"と"fuga"という2人のuser情報をinsertしていきます。
mysql> insert into users values(1, "hoge");
Query OK, 1 row affected (0.007 sec)
mysql> insert into users values(2, "fuga");
Query OK, 1 row affected (0.004 sec)下記コマンドでinsertされていることを確認。
mysql> select * from users;
+----+------+
| id | name |
+----+------+
| 1 | hoge |
| 2 | fuga |
+----+------+
2 rows in set (0.001 sec)MySQLの基本操作(CRUD)
以下では先ほどのコマンドを含む、MySQLでよく使う基本的なコマンドや操作(CRUD)をまとめていきます。
CRUDとは、データベース操作の基本であるCreate(作成)、Read(読み取り)、Update(更新)、Delete(削除)の頭文字をとった略語です。
これらの操作は、永続的なデータを持つほとんどすべてのアプリケーションやデータベースシステムに不可欠な機能であり、データの追加、参照、変更、削除を包括的に表します。
データベースの選択
アクセスしたいデータベースを指定します。
mysql> USE databasename;※データベースの選択をしていないと次以降のコマンドは動きません。
テーブルの一覧表示
選択したデータベース内に存在する全てのテーブルを表示します。
mysql> SHOW TABLES;テーブルの作成
先ほどやったように、データを格納するためのテーブルを作成します。
mysql> CREATE TABLE users(
id INT(10) NOT NULL,
name VARCHAR(30) NOT NULL,
PRIMARY KEY(id)
);テーブル構造を確認
テーブルのカラム名、データ型、キー情報などが確認できます。
mysql> DESC users;データの挿入
データをテーブルに挿入します。INSERT文を使用します。
mysql> INSERT INTO users values(1, "hoge");複数同時に入れることもできます。
mysql>INSERT INTO users
VALUE (2, "fuga"), (3, "piyo");データの並び替え
データを並び替えます。ORDER BYを使用します。
mysql> SELECT * FROM users ORDER BY id DESC;idの降順で並び替えます。
条件の絞り込み
データを絞り込みます。WHEREを使用します。
mysql> SELECT * FROM users WHERE name LIKE '%a%';nameに「a」を含むデータを取得します。
データの検索
データを検索します。SELECT分を使用します。
mysql> SELECT * FROM users;カラムを指定することも可能です。
mysql> SELECT name FROM users;条件をつけるときはWHERE句を使用します。
SELECT * FROM users WHERE id = 1;データの更新
データを更新します、UPDATE文を使用します。
mysql> UPDATE users SET name = 'piyo' WHERE id = 1;※WHEREをつけ忘れると全件更新してしまうので注意が必要です
データの削除
データを削除します。DELETE文を使用します。
mysql> DELETE FROM users WHERE name='piyo';テーブルの削除
テーブルを削除します。DROP文を使用します。
mysql> DROP TABLE users;データベースの削除
データベースを削除します、DROP文を使用します。
mysql> DROP DATABASE databasename;以上が実務でほぼほぼ確実に使うコマンドになります。
上記で書いた内容は全て覚えるようにしましょう。
次の章では中級編の「テーブルの結合」、リレーションとJOINについて紹介していきます。
テーブル同士を結合(JOIN)、リレーションの基礎から実践まで
基本操作のCRUDをマスターしたら次はデータの「結合」について学んでいきます。
MySQLではテーブル同士を関係づけて複雑なクエリを組むことができます。
この章では、まずリレーション(関係)の基礎を説明して、JOINの使い方をステップバイステップで紹介していきます。
リレーションとは?テーブル同士の繋がりを理解する
データベースの「リレーション」とは、テーブル同士の関係性を指します。データを効率的に整理するための仕組みで主に以下の3種類に分けられます。
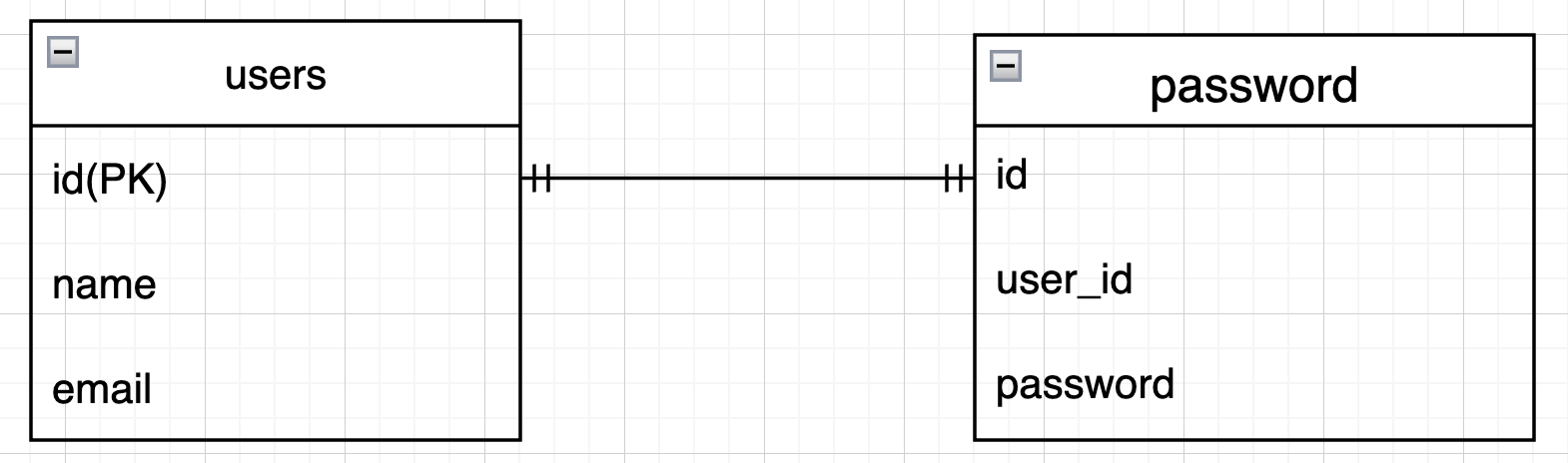
- 1対1(One-to-One): 1つのレコードがもう1つのテーブルに1つだけ対応。例: ユーザーとパスワード(セキュリティで別テーブルに分ける場合)。
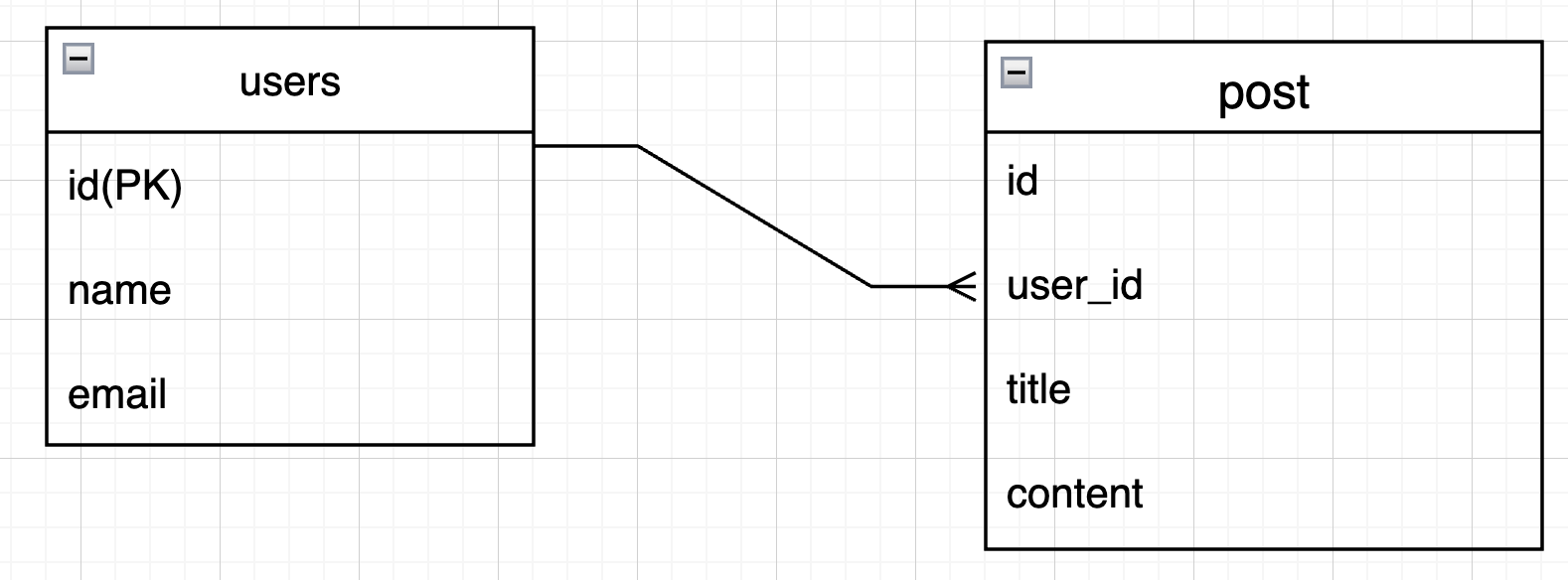
- 1対多(One-to-Many): 1つのレコードが複数のレコードに対応。 例: 1人のユーザーが複数の投稿(posts)を持つ。
- 多対多(Many-to-Many): 複数対複数。例: ユーザーが複数のグループに所属し、グループに複数のユーザーがいる。解決策は中間テーブル(junction table)を使う。
なぜテーブルを分けるか。それはデータを重複せずに保存できるからです。
例えば、'users'テーブルに投稿内容のデータを追加すると、ユーザー名が変更されたときに全投稿を'UPDATE'しなくてはなりません。
しかし、リレーションで分離すれば、'users'の'name'だけ変えればOKです。
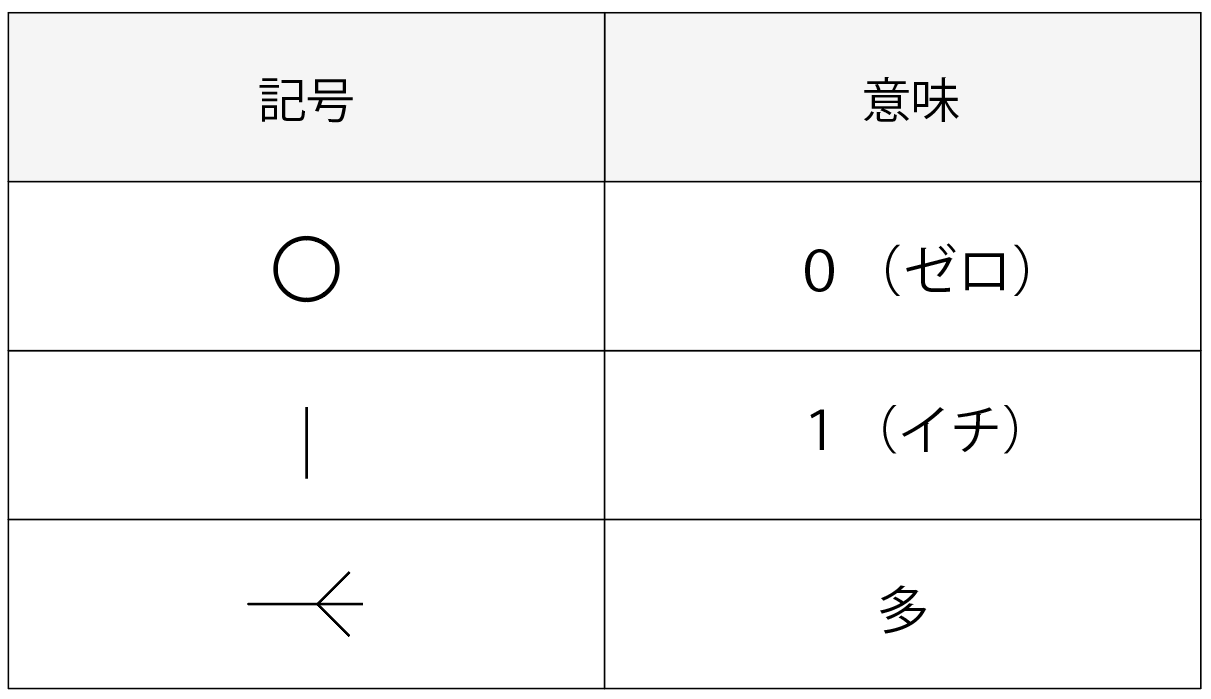
ER図には原則として以下の決まり事があります。
これを元にER図を書いていきます。
1対1
2つのテーブルを直線で繋ぎ、1の関係を表す縦棒「|」を書き加えます。
1対多
この場合、users テーブルの1行に対して、post テーブルの複数行が紐づきます。
多対多
この場合、直接2つのテーブルを繋げるとデータが重複しやすくなるので、中間テーブル(junction table)を挟んで解決します。
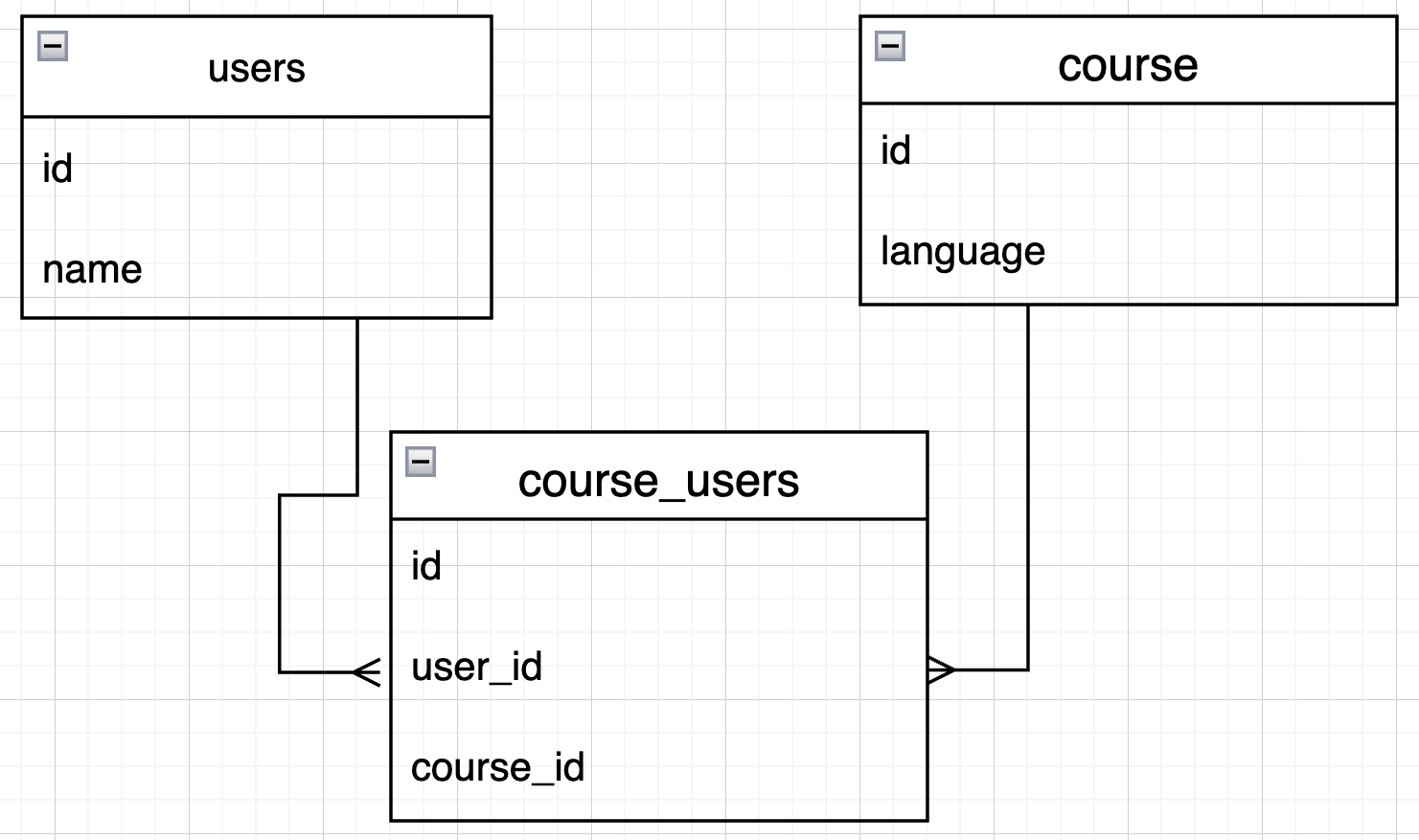
例えば、usersとcourseの関係で、1人のユーザーが複数のコースを受講し、1つのコースに複数のユーザーが在籍する場合、
中間テーブル「course_users」にuser_idとcourse_idの両方を入れて、橋渡し役にします。
JOINの基本、テーブルを結合してデータをまとめて取得する
データベースで複数のテーブルを結合する際に使われる JOIN(ジョイン)。
SQLの中でも重要な概念ですが、初学者には 「INNER JOINとLEFT JOINの違いは?」「OUTER JOINって何?」 など、少し分かりにくい部分もあります。
以下でその使い分け等ご紹介していきます。
JOINとは?
JOINとは、複数のテーブルを結合して1つの結果セットを作成する SQLの機能です。
リレーショナルデータベースでは、データを複数のテーブルに分けて管理 するため、必要に応じてデータを結合する必要があります。
例えば、以下の users テーブルと postsテーブルを用意します。
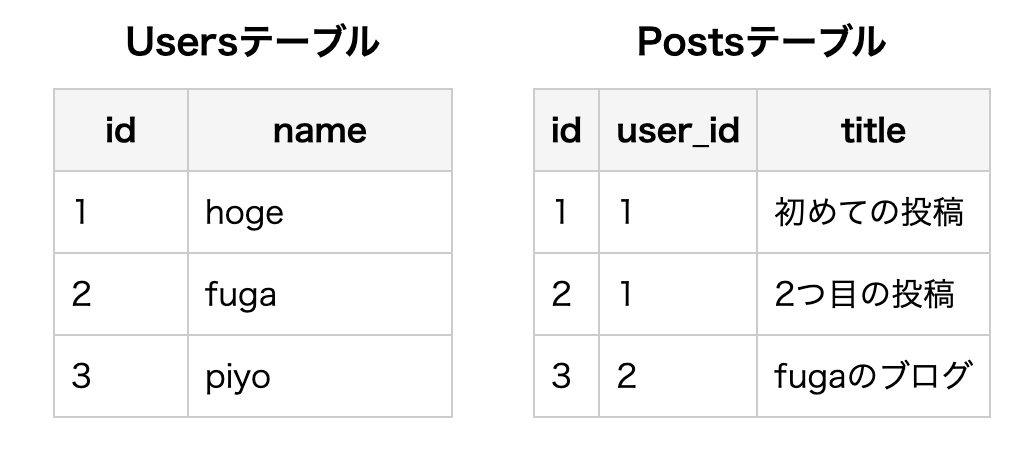
この2つのテーブルを結合して「ユーザー名」と「投稿タイトル」を取得 する場合にJOINを使います!
JOINの種類と使い方
SQLのJOINには、以下の4種類があります。
JOINの種類 | 説明 |
|---|---|
INNER JOIN | 両方のテーブルに一致するデータだけを取得 |
LEFT JOIN | 左側のテーブルのデータをすべて取得し、一致しない場合はNULL |
RIGHT JOIN | 右側のテーブルのデータをすべて取得し、一致しない場合はNULL |
CROSS JOIN | 両方のテーブルのすべての組み合わせ(直積)を取得 |
それでは1つずつ見ていきます。
INNER JOIN(内部結合)
特徴
- INNER JOINは両方のテーブルで一致するデータのみを取得する。
- 一致しないデータは無視される
SQL
SELECT users.name, posts.title
FROM users
INNER JOIN posts
ON users.id = posts.user_id;結果
name | title |
|---|---|
hoge | 初めての投稿 |
hoge | 2つ目の投稿 |
fuga | fugaのブログ |
LEFT JOIN(左外部結合)
特徴
- 左側のテーブル(users)のデータはすべて取得
- 一致するデータがない場合は NULL が入る
SQL
SELECT users.name, posts.title
FROM users
LEFT JOIN posts
ON users.id = posts.user_id;結果
name | title |
|---|---|
hoge | 初めての投稿 |
hoge | 2つ目の投稿 |
fuga | fugaのブログ |
piyo | NULL |
RIGHT JOIN(右外部結合)
特徴
- 右側のテーブル(users)のデータはすべて取得
- 一致するデータがない場合は NULL が入る
SQL
SELECT users.name, posts.title
FROM users
RIGHT JOIN posts
ON users.id = posts.user_id;結果
name | title |
|---|---|
hoge | 初めての投稿 |
hoge | 2つ目の投稿 |
fuga | fugaのブログ |
CROSS JOIN(クロス結合)
特徴
- 両方のテーブルのすべての組み合わせを取得
- 条件がないため、データ量が爆発的に増える
SQL
SELECT users.name, posts.title
FROM users
CROSS JOIN posts;結果
name | title |
|---|---|
hoge | 初めての投稿 |
hoge | 2つ目の投稿 |
fuga | fugaのブログ |
piyo | NULL |
【補足】エイリアス(AS)でクエリを読みやすく
JOINを多用するとSQLが長くなりがちになります。
テーブルに短い別名(エイリアス)をつけて整理します。
SELECT u.name, p.title
FROM users AS u
INNER JOIN posts AS p
ON u.id = p.user_id;エイリアスを使うことで、SQLがすっきりして読みやすくなります。
サブクエリ(副問い合わせ)
サブクエリ(副問合せ)とは?
サブクエリ(副問い合わせ)とは、クエリの中で使用される別のクエリのことを指します。
サブクエリを使用すると、複雑な条件を持つクエリを簡潔に表現でき、データの抽出や加工をより柔軟に行うことができます。
基本構文
サブクエリは、メインクエリのSELECT、FROM、WHERE、HAVING、INSERT、UPDATE、DELETE文の中で使用することができます。
基本的な構文は以下の通りです。
SELECT カラム1, カラム2, ...
FROM テーブル名
WHERE カラム = (SELECT カラム FROM 他テーブル名 WHERE 条件);具体的なコードを見ながら、サブクエリの利用時を紹介していきます。
条件式におけるデータ絞り込み
WHERE句やHAVING句の中でサブクエリを使用すると、データ抽出の条件をより細かく指定することができます。
例えば、平均金額以上の注文をした注文を抽出したい場合、次のように記述できます。
SELECT *
FROM orders
WHERE total_price >= (
SELECT AVG(total_price)
FROM orders
);この例では内側のクエリで平均金額を求め、外側でその値以上の注文を取得しています。
比較系サブクエリの典型例です。
データの追加におけるデータ取得
INSERT文でサブクエリを使用すると、他のテーブルからデータを取得して、新しいレコードを作成することができます。
例えば、顧客情報テーブルに、注文情報テーブルから取得した最新の注文日時を追加する場合、次のように記述できます。
INSERT INTO customers (customer_name, last_order_date)
SELECT customer_name, MAX(order_date)
FROM orders
GROUP BY customer_name;この例では、サブクエリが、各顧客の最新の注文日時を取得し、INSERT文によって新しいレコードに反映されます。
データの更新におけるデータ取得
UPDATE文でサブクエリを使用すると、他のテーブルからデータを取得して、既存のレコードを更新することができます。
例えば、特定の製品の価格を、同じカテゴリの製品の平均価格に更新したい場合、次のように記述できます。
UPDATE products
SET price = (SELECT AVG(price) FROM products WHERE category = 'Electronics')
WHERE category = 'Electronics';この例では、サブクエリが同じカテゴリの製品の平均価格を取得し、UPDATE文のSET句の中で使用しています。
つまりサブクエリは、外側のSQL文に更新対象の値(この場合は平均価格)を提供する役割を果たしています。
データの削除におけるデータ取得
DELETE文でサブクエリを使用すると、他のテーブルからデータを取得して、特定のレコードを削除することができます。
例えば、特定の顧客の注文履歴を削除する場合、次のように記述できます。
DELETE FROM orders
WHERE customer_id
IN (SELECT customer_id FROM customers WHERE customer_name = 'John Doe');この例では、サブクエリが特定の顧客のIDを取得し、DELETE文のWHERE句の中で使用されています。
サブクエリは、外側のSQL文に削除対象のレコードを特定するための情報を提供しています。
サブクエリの注意点
サブクエリの使用にはいくつかの注意点があります。
パフォーマンスへの影響
サブクエリは、通常のSQL文よりも処理時間がかかる場合が多いです。
先ほどの例でも、同じカテゴリの製品のレコードが大量にあった場合、それだけで処理が重くなります。
その場合は、適切なインデックスを設定したり、クエリを分割して実行することで結果処理が早まることもあります。
SQL文の複雑化
サブクエリは複数組み合わせることも可能ですが、ネストさせたSQL文は非常に複雑になりやすく、他者が見た際に理解しづらくなる場合があります。
サブクエリを使う際は、可読性を意識しながら、適切に利用することが重要です。
データ設計の基礎(正規化)
MySQLで効率的なクエリを書くためには、まず「正しいデータ構造」が必要です。
テーブル設計が甘いと、どんなにクエリを最適化しても遅くなります。
正規化とは
データの重複をなくし整合的にデータを取り扱えるようにデータベースを設計することを、データベースの正規化と呼びます。
正規化を行っておくと、データの追加・更新・削除などに伴うデータの不整合や喪失が起きるのを防ぎ、メンテナンスの効率を高めることができます。
正規化の段階には、第1~第5正規形およびボイスコッド正規形がありますが、
この章では、データベースを設計する際に一般的に用いられる第1~第3正規形までを説明していきます。
第1正規形
正規化について具体的に見ていくためにECサイトのような注文を管理するテーブルを想定します。

山田さんは1回の注文で2つの商品を購入したため、上のテーブルでは商品IDと商品名、数量に2つの値が入ってしまっています。(非正規形)
第1正規形では1つのセルには1つの値しか含まれない状態にする必要があります。
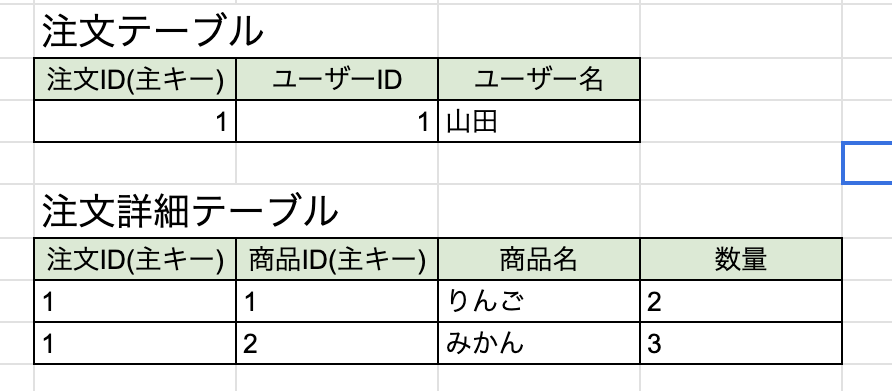
このように、繰り返し部分を切り離して独立させることで第1正規形に正規化しました。
第2正規形
第2正規形では、第1正規形の状態から部分関数従属を除いて完全関数従属の状態にします。
関数従属性とは
関数従属とはあるXの値を定めると、Yの値が一意に決まる関係のことをいいます。
社員番号が「001」の場合、その社員の名前は「田中」さんと決まるような関係のことを指します。
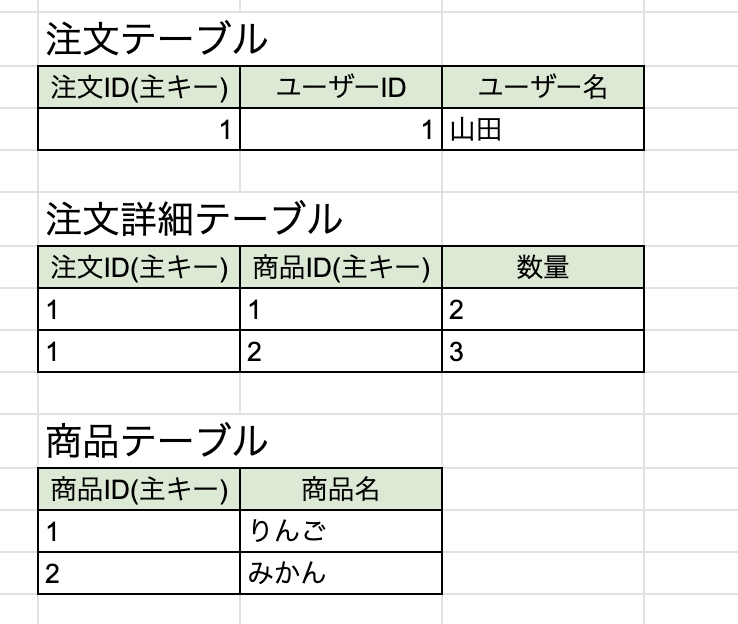
部分関数従属は、ある属性が複数の主キーのいずれかに関数従属している状態です。
今回の例で言うと、注文詳細テーブルの複合キーの一部である商品IDが決定すれば商品名が決まるところが部分関数従属です。
第2正規形ではここを別テーブルに分離させます。
第3正規形
第3正規形では、第2正規形の状態から推移的関数従属を除きます。
推移的関数従属とは
推移的関数従属は、関数従属が推移的に成立する関係のことです。
「Aが決まるとBが決まって、Bが決まるとCが決まる」という関係です。
今回の例でいうと、注文テーブルの注文IDが決まるとユーザーIDが決まり、ユーザーIDが決まるとユーザー名が決まる部分が推移的関数従属です。
第3正規形ではここを別テーブルに分離します。

まとめ
非正規化だったテーブルを4つのテーブルに分割して正規化を行いました。
要点としては以下になります。
- 第1正規形:繰り返し部分がない状態
- 第2正規形:第1正規形から部分関数従属を排除
- 第3正規形:第2正規形から推移的関数従属を排除
正規化は統合性の観点からすればメリットがありますが、テーブルの数が増えるのでパフォーマンスが低下したり管理が複雑になったりするデメリットもあります。
要件に合わせて柔軟に設計することが大切です。
データベースのインデックス
データベースを使っていると、「クエリの実行が遅い」「データ量が増えると検索に時間がかかる」という問題が起こります。
そんなときに役立つのが 「インデックス(索引)」 です。
インデックスとは
インデックスとは、データ検索を高速化するための仕組み です。
本の索引のように「どの行がどこにあるか」を覚えておくことで、
テーブル全体を走査せずに目的の行を探せます。
インデックスの種類と使い方
データベースには、用途に応じた さまざまな種類のインデックス があります。
ここでは、代表的な以下の5種類のインデックス を紹介していきます
種類 | 特徴 |
|---|---|
PRIMARY KEY | 主キー。自動的にクラスタ化インデックスになる |
UNIQUE | 値の重複を禁止(例:メールアドレス) |
INDEX | 一般的な検索用インデックス |
FULLTEXT | 文章検索用 |
COMPOSITE INDEX(複合) | 複数カラムをまとめてインデックス化 |
主キーインデックス(Primary Key Index)
特徴
- 主キー(PRIMARY KEY)に設定すると、自動的に作成されるインデックス
- 一意性(ユニーク)を保証 し、NULLを許可しない
- クエリの検索性能を向上させる
SQL
CREATE TABLE users (
id INT PRIMARY KEY, -- 主キーインデックスが自動的に作成される
name VARCHAR(100),
email VARCHAR(100)
);どんな時に使う?
- 各行を一意に識別するために使用
- 主キーを使った検索が多い場合に有効
注意点
- 主キーに設定すると、自動的にインデックスが作成されるため、明示的にインデックスを追加する必要はない
ユニークインデックス(Unique Index)
特徴
- 一意性を保証するインデックス(重複を防ぐ)
- NULL を許可することができる(ただし、データベースによって動作が異なる)
SQL
CREATE TABLE users (
id INT PRIMARY KEY,
email VARCHAR(100) UNIQUE -- ユニークインデックスが作成される
);どんな時に使う?
- メールアドレスやユーザー名など、重複してはいけないデータ に使用
- データの整合性を保証しつつ、高速な検索を実現
注意点
- 一意制約があるため、重複するデータを挿入できない
通常インデックス(Index)
特徴
- 検索を高速化するために手動で作成するインデックス
- 主キーやユニーク制約がないカラムにも適用可能
SQL
CREATE INDEX idx_users_name ON users(name);どんな時に使う?
- WHERE 句で頻繁に検索されるカラム に使用(例:name、email)
- JOIN や ORDER BY のパフォーマンスを向上 させる
注意点
- INSERT / UPDATE / DELETE の速度が低下する(インデックスの更新が必要になるため)
- 不要なインデックスを作りすぎると、パフォーマンスが悪化する
全文検索インデックス(Full-Text Index)
特徴
- テキスト検索に特化したインデックス
- 部分一致検索(LIKE '%文字列%')より高速
- 検索結果のスコアリングが可能
SQL
CREATE FULLTEXT INDEX idx_users_bio ON users(bio);検索する時
SELECT * FROM users WHERE MATCH(bio) AGAINST('エンジニア');どんな時に使う?
- 記事・ブログ・コメントなど、長文のテキスト検索
- 通常のインデックスでは対応できない「単語単位」の検索
注意点
- データの更新が頻繁な場合はパフォーマンスに影響が出る
- データベースによっては全文検索をサポートしていない(例:SQLite)
複合インデックス(Composite Index)
特徴
- 複数のカラムを組み合わせたインデックス
- 複数の条件を組み合わせた検索を高速化できる
SQL
CREATE INDEX idx_users_name_email ON users(name, email);どんな時に使う?
- 複数のカラムを条件にした検索が多い場合
- ORDER BY で並び替えが多い場合
注意点
- インデックスの順番が重要(name, email の順番で作った場合、email 単体の検索には最適化されない)
トランザクション
MySQLを学ぶ上で避けて通れないのが「トランザクション」。
アプリケーションで“お金を移動させる”“在庫を更新する”など、一連の操作をまとめて扱う場面では必須の概念です。
トランザクションとは
トランザクションとは、「複数の処理を一つの処理として一貫性を持たせて実行・管理する仕組み」のことを言います。
データの整合性を保つために重要な仕組みとなっています。
トランザクションの4つの条件
トランザクション処理にはACID特性という、データベースの安定性と整合性を確保するための基本的な要件があり、具体的には下記4つの条件を提供します。
原子性(Atomicity)
トランザクション内のすべての操作が、すべて成功するか、すべて失敗するかを保証します。
部分的に成功することはなく、「すべてか、なにもないか」のどちらか。
例: 銀行の送金で、残高引き落としと相手口座への入金が両方成功しない場合、両方とも取り消される(ロールバック)。
一貫性(Consistency)
トランザクションの実行前後で、データベースの状態が制約(例: キー制約、チェック制約)を満たす状態を保ちます。
トランザクションが正しく終了すれば、データベースは一貫した状態になります。
例: 社員テーブルの給与合計が常に正の値になる制約を守る。
独立性(Isolation)
複数のトランザクションが同時に実行されても、互いに干渉せず、独立して動作します。
他のトランザクションの途中結果が見えないようにします。
例: 2つのユーザーが同時に在庫を更新しても、片方の変更が他方に影響を与えない。
永続性(Durability)
トランザクションがコミットされた後、システム障害が起きても、変更が永続的に保存されます。
例: コミット後にサーバーがクラッシュしても、データは失われない。
トランザクションの書き方
トランザクションを張るには、更新する DML 文(INSERT / DELETE / UPDATE)を
- トランザクション開始文
- トランザクション終了文
で囲う必要があります。
トランザクション開始文;
-- DML①;
-- DML②;
-- ...
トランザクション終了文;トランザクション開始文
MySQL のトランザクション開始文はSTART TRANSACTION;を使用します。
START TRANSACTION;
-- DML①;
-- DML②;
-- ...
トランザクション終了文;トランザクション終了文
トランザクション終了文はCOMMIT;またはROLLBACK;を使用します。
- COMMIT;:更新を確定して DB に反映をする
- ROLLBACK;:更新を全て破棄し、トランザクション前の状態に戻す
START TRANSACTION;
-- DML①;
-- DML②;
-- ...
COMMIT; -- 成功(確定)
-- または
ROLLBACK; -- 失敗時は元に戻すトランザクションの使用例
実際に MySQL でトランザクションを「AさんからBさんに1万円送金」という例に沿って使用してみます。
- 口座 A から ¥10,000 を引き落とす
- 口座 B に ¥10,000 を入金
UPDATE accounts SET balance = balance - 10000 WHERE id = 1; -- Aさんの口座
UPDATE accounts SET balance = balance + 10000 WHERE id = 2; -- Bさんの口座上記2つの処理では「両方成功」か「両方失敗」でないといけません。
どちらか片方だけが実行されてしまうとお金が消えるか二重に増えてしまいます。
これを安全に制御するのがトランザクションです。
START TRANSACTION; -- トランザクション開始
UPDATE accounts SET balance = balance - 10000 WHERE id = 1;
UPDATE accounts SET balance = balance + 10000 WHERE id = 2;
COMMIT; -- 成功(確定)
-- または
ROLLBACK; -- 失敗時は元に戻すセキュリティ対策
MySQLを学習する中で、基礎的な操作(CRUDやJOIN)をマスターしたら、次に大事なのがセキュリティです。
データベースは個人情報やビジネスデータを扱うことが多く、適切な対策を怠るとSQLインジェクションなどの攻撃でデータ漏洩や改ざんのリスクが生じるからです。
具体的には、パスワードの管理やアクセス制限などがあります。ここからは、具体的な対策方法を紹介していきます。
強力なパスワードを設定する
データベースのユーザーアカウントに強力なパスワードを設定することが大切です。
短いパスワードや簡単に推測できるパスワードは避けて、長くて複雑なもの(大文字・小文字・数字・記号混在、8文字以上)にしましょう。
mysql> ALTER USER 'hoge'@'host'IDENTIFIED BY '強力なパスワード';不要なユーザーを削除する
デフォルトで存在する匿名ユーザー(空のユーザー名)やテストアカウントは、不正アクセスの入口になるので削除しましょう。
mysql> DROP USER ''@'localhost'; -- 匿名ユーザー削除
mysql> DROP USER '不要なユーザー名'@'ホスト名';特定のIPアドレスだけにアクセスを許可する
全ホスト('%')からの接続を避け、特定のIPやlocalhostに制限することで、不正なアクセスを防ぐことができます。
mysql> CREATE USER 'hoge'@'特定の.IP.アドレス' IDENTIFIED BY 'パスワード';
mysql> GRANT ALL PRIVILEGES ON データベース名.* TO 'hoge'@'特定の.IP.アドレス';権限を最小限にする
ユーザーに全権限(ALL PRIVILEGES)を与えず、必要な操作だけ指定。例: 読み取り専用ユーザーにはSELECTのみ。
mysql> GRANT SELECT, INSERT ON データベース名.* TO 'hoge'@'host';既定のポート番号を変更する
MySQLのデフォルトポート(3306)は攻撃ツールの標的にされやすいので、変更してスキャンを回避しましょう。
# MySQLの設定ファイル (my.cnf または my.ini) を編集
[mysqld]
port=新しいポート番号SQLインジェクションを防ぐ
アプリ連携時、ユーザー入力を直接SQLに埋め込まない。プリペアドステートメントを使いましょう(PHP例)
$stmt = $pdo->prepare("SELECT * FROM users WHERE name = ?");
$stmt->execute([$input]); // 自動エスケープバックアップとリカバリ
セキュリティ対策の次はバックアップとリカバリです。
MySQLは障害(サーバークラッシュ、誤削除、人為的ミス)でデータが失われるリスクがあるので、定期的なバックアップが命綱となります。
データベースからデータをバックアップするには主に2つの方法があります。
論理バックアップ
論理バックアップは、データの復元に必要な SQL ステートメントで構成されます。この種類のバックアップは、情報およびレコードをプレーンテキストファイルにエクスポートします。
物理バックアップに対する論理バックアップの主な利点は、移植性と柔軟性です。
データは、物理バックアップではできない他のハードウェア設定である MySQL バージョンまたはデータベース管理システム (DBMS) で復元できます。
論理バックアップには、ログと設定ファイルが含まれません。
物理バックアップ
物理バックアップは、コンテンツを格納するファイルおよびディレクトリーのコピーで構成されます。
物理バックアップは、論理バックアップと比較して、以下の利点があります。
- 出力が少なくなる。
- バックアップのサイズが小さくなる。
- バックアップおよび復元が速くなる。
- バックアップには、ログファイルと設定ファイルが含まれる。
mysqldumpを使用した論理バックアップ
mysqldumpはデータと構造をSQL形式で出力するツール。
データベースの内容をSQL形式で書き出し、後から復元できるようにします。
-u: ユーザー
-p:パスワード
mydb:データベース名
backup.sql:バックアップファイル名(自由に入力可能)
- 単一DBのフルバックアップ
mysqldump -u root -p mydb > backup.sql- 全DBバックアップ
mysqldump -u root -p --all-databases > backup.sqlバックアップの復元
バックアップファイルからデータを復元。
- 単一DBの復元
mysql -u root -p mydb < backup.sql※あらかじめ空のデータベースを作成しておく
CREATE DATABASE mydb;- 全DB復元
mysql -u root -p < backup.sqlクエリの最適化(パフォーマンスチューニング)
データが少ないうちは問題なく動作しますが、テーブルのレコード数が増えてくると「処理が遅い」「ページの読み込みが重い」といった問題が発生します。
ここでは、MySQLのクエリを高速化するための基本的な最適化方法を紹介します。
なぜクエリ最適化が必要か
- データ量が増えると、単純なSELECTでも急に遅くなる
- 不要な結合・サブクエリが、CPUやメモリを圧迫
- 適切なインデックスがないと、全件走査(フルスキャン)が発生
クエリ最適化とは、これらの問題を見つけ、より効率的にデータを取得する仕組みを作ることです。
以下ではクエリを最適化する方法を紹介していきます。
インデックス(INDEX)を活用する
インデックスとは、検索を高速化するための仕組みです。
本でいう「目次」のようなもので、テーブル全体を1行ずつ探す(フルスキャン)ことなく、目的の行をすぐに見つけられます。
-- usersテーブルのnameカラムにインデックスを追加
CREATE INDEX idx_name ON users(name);これにより、以下のような検索が高速化されます
SELECT * FROM users WHERE name = 'hoge';※ただし、インデックスを付けすぎると「INSERT」「UPDATE」「DELETE」の処理が遅くなるため、
検索でよく使うカラムにだけ設定する。
SELECT *は使わない
SELECT *の使用は便利ですが、不要なカラムまで取得してしまうため、通信量が増え、パフォーマンスが低下します。。
必要なカラムだけを明示的に指定しましょう。
-- NG
SELECT * FROM users;
-- OK
SELECT id, name FROM users;LIMIT句で取得件数を制限する
大量のデータを一度に取得すると、メモリやネットワークの負担になります。
一覧画面などでは LIMIT を使って、必要な件数だけ取得しましょう。
SELECT * FROM users ORDER BY id DESC LIMIT 10;結合を効率的に使用する
リレーショナルデータベースを使用する場合、冗長性を避けて効率性を高めるために、データは別々のテーブルに整理されることがよくあります。
ただし、必要な関連情報をすべて取得するために、さまざまな場所からデータを取得してそれらを結合する必要があることを意味します。
結合にはさまざまな種類があり、それぞれの使用方法を理解する必要があります。
間違った結合を使用すると、データセットに重複が作成され、速度が低下する可能性があるので注意必要。
EXPLAINで実行計画を確認する
MySQLの EXPLAIN コマンドを使うと、SQLがどのように実行されているかを確認できます。
EXPLAIN SELECT * FROM users WHERE name = 'hoge';結果を見て「type」列が ALL の場合はフルスキャンをしているという意味です。
このような場合は、インデックスを設定して改善できる可能性があります。
不要なサブクエリを避ける
サブクエリは便利ですが、重くなりやすいです。
同じ結果がJOINで取得できる場合は、JOINを使うほうが効率的なケースが多いです。
-- サブクエリ(遅い場合がある)
SELECT name FROM users WHERE id IN (SELECT user_id FROM posts);
-- JOIN(高速)
SELECT u.name FROM users u
INNER JOIN posts p ON u.id = p.user_id;データ型を最適化する
カラムの型を適切に選ぶことも重要です。
必要以上に大きな型を使うと、無駄にメモリを消費します。
- 数値ID → INT(必要に応じて SMALLINT なども検討)
- 文字列 → 固定長なら CHAR、可変長なら VARCHAR
- フラグ → BOOLEAN または TINYINT(1)
キャッシュを活用する(上級者向け)
MySQLにはクエリキャッシュがあり、同じクエリを繰り返し実行する場合に結果を再利用できます。
ただし、MySQLのバージョンによっては無効化されていることもあるので、アプリ側でキャッシュを実装する方法(例:Redisなど)も検討できます。
まとめ
MySQLの最適化は、単に「速くする」だけでなく、
データ量が増えても安定して動く設計をすることが目的です。
まず次の3つを意識しましょう。
- よく検索に使うカラムにはインデックスをつける
- SELECT * は使わず、必要なカラムだけ指定する
- EXPLAIN で実行計画を確認する癖をつける